
Que o uso da IA Generativa tem gerado grandes impactos e que essa tecnologia é utilizada de várias, várias e váááárias formas diferentes não é novidade. Mas um fato que para mim foi surpreendente é o quanto a comoditização de Large Language Models (LLMs) tem mudado a forma como nós escrevemos e interagimos com software.
Escrever software em 2025 é muito diferente de escrever software em 2022 no período pré ChatGPT. Por exemplo: vamos supor que você está trabalhando com uma base de códigos (codebase) nova, com uma tecnologia que não conhece muito e, tentando implementar uma nova funcionalidade, esbarra com um erro muito chato e complicado e não faz ideia do porquê não está funcionando .
| Exercício de reflexão: O que você faria nessa situação? Quais são as opções que não envolvem utilizar IA? (pensa um pouco antes de olhar minha sugestão abaixo!) |
Normalmente, diante desse cenário, eu iria:
- Perguntar para alguém, que sabe muito dessa parte do código ou dessa tecnologia, o que o erro significa e como “debuggar”.
- Pesquisar o erro no Google + stackoverflow.
- Continuar investigando o erro, tentando entender melhor o problema (o famoso: encarar o código até algo ser revelado diretamente do Divino para você).
- Repetir todas as opções acima até resolver o problema.
Hoje em dia com LLMs, além de todas as ações acima, temos muito mais opções! Podemos:
- Explicar o problema e perguntar a Chatbots, como o ChatGPT, Gemini, Claude Sonnet etc.
- Utilizar soluções específicas diretamente na nossa IDE que tem acesso ao código: como o copilot, cursor, windsurf.
- Pedir para uma IA resolver o problema para a gente basicamente de forma autônoma. Essa é a proposta do Codex da OpenAI e do Jules do Google.
Seja qual for o aplicativo/ferramenta de IA em questão, é como se tivéssemos acesso a uma pessoa especialista disponível 24h por dia. E o melhor: que sabe bastante sobre a tecnologia, leu e “decorou” a internet inteira e, mesmo sem nunca ter visto a nossa codebase antes, consegue ler os arquivos relevantes em segundos e propor sugestões, próximos passos, e – quem sabe – até implementar uma solução completa!
Parece máááágicaaaa!! E, de fato, a tecnologia é realmente fascinante, mas para usarmos de forma segura e eficiente, precisamos entender quais são seus benefícios, limitações e potenciais riscos.
Esse artigo está organizado nas seguintes seções:
- Como a IA tem mudado a forma de se pensar e organizar software
- Como “fugir do hype” e usar IA Generativa de maneira eficiente
- Vibe Coding
- Agentes
- Conclusões
Antes de começar, um aviso: está fora do escopo deste artigo entrar em detalhes e comparar qual o melhor dos aplicativos para auxiliar no desenvolvimento com IA. Meu convite é para você explorar as opções e tentar, na prática, o que funciona para os seus casos de uso.
Vamos lá!
Como a IA tem mudado a forma de se pensar e organizar software
Em 2017, Andrej Karpathy (ex-diretor de IA da Tesla, além de um excelente comunicador e educador) escreveu um blog em que ele propôs um novo tipo de código: “software 2.0”.
No artigo ele explica que podemos categorizar código de duas formas:
- Software 1.0: código que nós escrevemos diretamente, ou seja, na sua forma tradicional. Por exemplo: um aplicativo para iphone para o jogo fruit ninja.
- Software 2.0: saídas geradas por redes neurais e modelos de Deep Learning. Por exemplo: em vez de implementar um algoritmo para detectar se um tweet tem tom negativo ou positivo dependendo das palavras utilizadas, podemos treinar uma rede neural que analisa o texto e nos dá o resultado como saída.
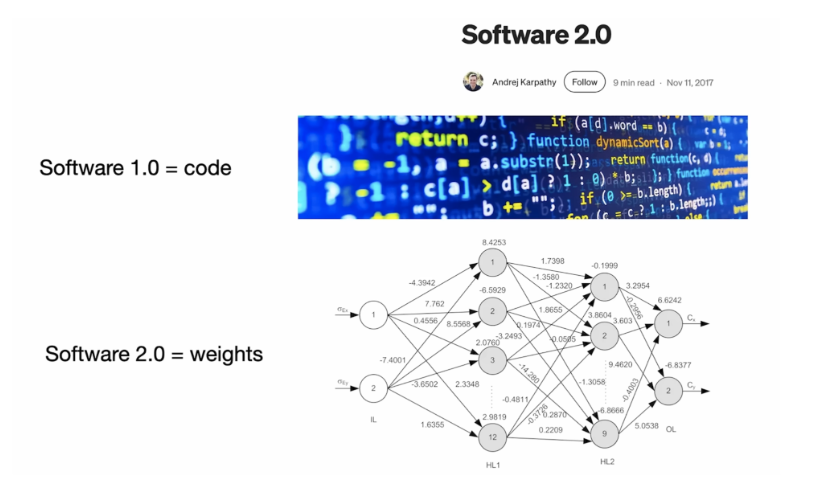
Recomendação: quer entender mais sobre redes neurais e da tecnologia por trás de LLMs como o ChatGPT? Recomendo assistir a essa palestra da Gabriela Surita para o Programaria: Do bit ao GPT: A tecnologia e a história por trás dos chatbots modernos
O principal ponto do artigo e dessa categorização é que essas diferentes formas de criar código possuem características bem distintas. O uso de redes neurais, em particular, representa uma mudança significativa na forma como produzimos software, exigindo uma reflexão crítica sobre em quais contextos cada abordagem deve ser aplicada.
| Exercício de reflexão: Exercício: Quais são algumas das diferenças que você consegue pensar em relação a “Software 1.0” e “Software 2.0”? A resposta está no artigo original aqui (em inglês), recomendo a leitura! |
Há algumas semanas, Karpathy apresentou uma nova palestra intitulada “Software está mudando! (De novo!)” (disponível no youtube, recomendo!) em que ele retoma essa questão, mas agora introduzindo uma nova categoria de código: “Software 3.0”.
O Software 3.0 consiste basicamente em utilizar LLMs diretamente para resolução de problemas, em vez de implementar nosso próprio algoritmo ou treinar nossa própria rede neural. Podemos até mesmo utilizar LLMs para gerar Software 1.0 ou Software 2.0!
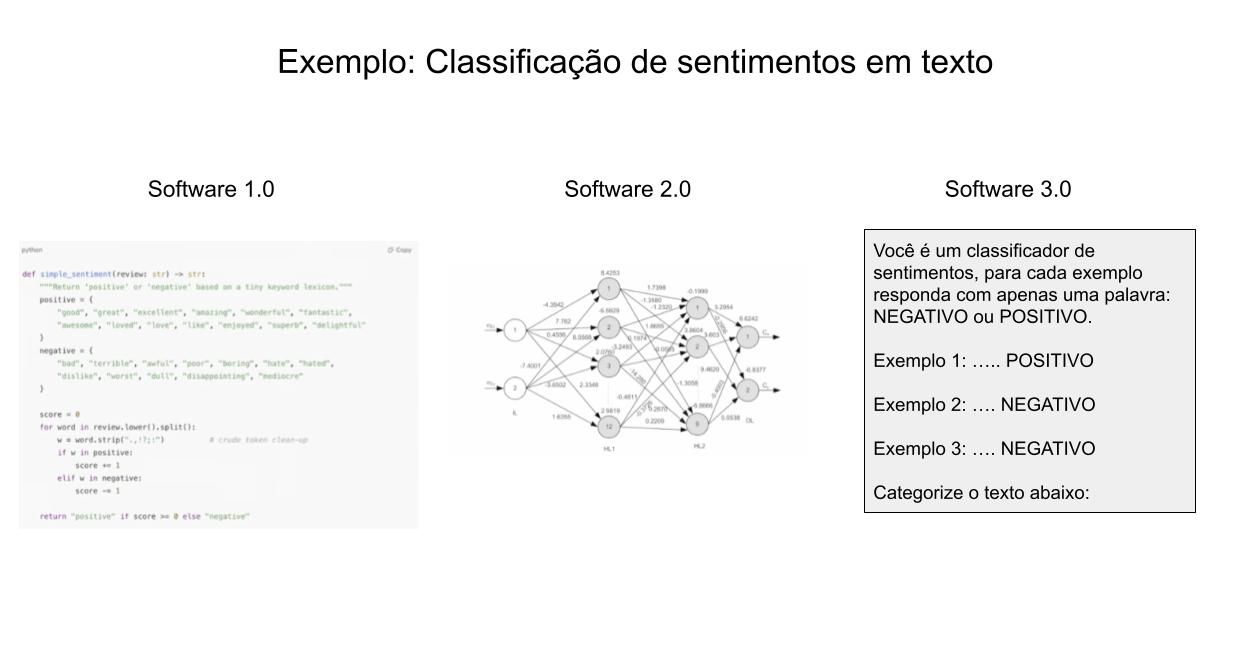
Adaptei um dos slides da palestra na imagem acima. São comparadas diferentes implementações de um algoritmo para classificação de sentimentos utilizando cada um dos “tipos de software”.
Para mim, uma das formas mais interessantes de se pensar em LLMs como sendo esse “Software 3.0” é entendê-los como uma maneira complementar ao modo tradicional de se desenvolver software.
Da mesma forma que uma calculadora ou um programa em python são muito mais rápidos do que nós em realizar várias operações matemáticas em sequência e lembrar do resultado, esses modelos são excepcionais em ingerir uma grande quantidade de texto em segundos e extrair informações (com suas limitações, claro – falaremos disso em mais detalhes na próxima seção).
Com LLMs, temos inúmeras possibilidades de criar software com muito mais facilidade! Nas próximas seções irei falar especificamente em ferramentas e tendências de IA generativa para o desenvolvimento de software.
Como “fugir do hype” e usar IA Generativa de maneira eficiente
Como mencionei rapidamente no início, há várias soluções com LLMs que podem ser usadas para tornar nossa experiência como pessoas desenvolvedoras mais agradável e eficiente. Algumas soluções são mais modernas, especializadas e poderosas (por exemplo: algumas ferramentas podem executar testes ou colocar um site em produção por você), outras são mais simples e não necessariamente específicas para desenvolvimento de código (por exemplo: posso copiar e colar um código para o ChatGPT e fazer uma pergunta a respeito de uma mensagem de erro).
Apesar desse extenso leque de aplicativos, como GUIs, CLIs etc., todas as soluções que iremos discutir são baseadas em LLMs, então, de certa forma apresentam os mesmos benefícios e limitações.
Existem vários tutoriais explicando em detalhes o que são Large Language Models, como são treinados etc. Mas, para o contexto deste artigo, não irei entrar em detalhes técnicos; vou abordar quais são seus pontos fortes (qualidades) e pontos fracos (limitações).
Qualidades dos LLMs modernos
- São experts nas linguagens de programação, bibliotecas e frameworks mais conhecidos e populares. Sabem a sintaxe, como corrigir erros comuns, quais padrões de qualidade esperar etc.
- Podem ingerir uma grande quantidade de texto como entrada: a maioria pode receber mais de 100.000 palavras como entrada, sem problemas!
- Rápida interação. Você consegue interagir em tempo real com esses modelos e paralelizar o trabalho.
Limitações dos LLMs modernos
- Esses modelos só têm acesso ao que você dá como entrada; e esse é o principal ponto para se ter em mente quando usamos LLMs. Em outras palavras, na maioria das iterações com AI Generativa, os modelos são “passivos” e só têm o contexto da entrada textual para produzir a saída. Nesse sentido, soluções que têm acesso direto a seu código, como por exemplo o GitHub Copilot, têm uma grande vantagem, já que o contexto, muitas vezes, pode ser inferido a partir do código.
- LLMs não são perfeitos, cometem erros, inventam fatos e, o pior de tudo, não sabem que não sabem. Ou seja, tendem a ser extremamente confiantes, mesmo quando estão errados!! Esse fenômeno dos LLMs inventarem fatos é tão comum, que tem um termo próprio: “alucinação”. Sempre devemos conferir se a saída dos LLMs realmente estão corretas e fazem sentido.Segue um exemplo com o Gemini 2.5:

Podemos verificar a resposta contando manualmente ou com um simples programa em Python:
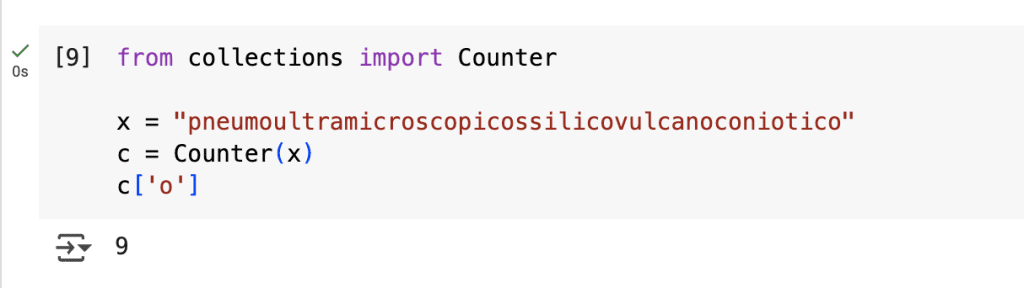
Quando usamos LLMs para gerar código (especialmente em um código bastante especializado), por exemplo, é comum que o modelo comece a alucinar sintaxe, funções, classes ou objetos.
- LLMs são basicamente treinados em dados e texto disponíveis na internet e a internet não é uma representação de uma distribuição perfeita de tudo que existe no mundo real. Dessa forma:
- Quanto menos comum e mais especializado for o código e tecnologias utilizadas no seu caso de uso, maior a probabilidade do LLM alucinar e não ser tão útil no seu contexto.
- Novas versões de bibliotecas ou tecnologias recentes podem não estar representadas nos dados de treino dos modelos de IA. Isso pode resultar em resultados defasados (por exemplo: sugerindo utilizar uma feature que foi depreciada ou não mais recomendada) ou ainda resultar em mais alucinações.
Com base nessas qualidades e limitações, seguem algumas dicas de como utilizar AI Generativa para auxiliar o desenvolvimento de software de forma eficiente.
Dicas gerais
- Não economize palavras para descrever o problema ou solução esperada (exemplo: que bibliotecas usar, qual a entrada e saída esperada, qual a mensagem de erro detalhada etc.). Passe o máximo de detalhes possíveis, especialmente se você sabe como seria a solução ideal e quer apenas economizar tempo na implementação. Prover esses detalhes vai economizar tempo de ter que “corrigir” a IA depois.
- Use LLMs para debugar. LLMs são ótimos patos de borracha! Usar IA para debugar e debater soluções tende a ser bem produtivo na minha experiência. Mas evite enviesar o modelo sobre qual o problema. Em vez disso, peça sugestões e verifique se suas hipóteses fazem sentido.
- Quebre a tarefa em subtarefas menores e mais simples, e prossiga de forma incremental até chegar na solução. Evite pedir para o modelo realizar tarefas complexas de uma só vez.
- Importante: se você não tem uma ideia de como será a solução, antes de gerar código é melhor pedir sugestões de abordagens (por exemplo: perguntar quais tecnologias e bibliotecas utilizar, como implementar, como verificar se a solução está correta etc.), dessa forma, você pode corrigir a IA antes de vários erros serem cometidos.
- Lembre-se de que você é quem está “pilotando” o desenvolvimento, então, tenha cuidado com o seu tempo. Se você tentou resolver um problema com uma LLM duas, três vezes, e não obteve resultado, provavelmente é hora de tentar outra abordagem.
- Cuidado com o compartilhamento de informações sigilosas e código privado. Afinal esses modelos são (em sua grande parte) servidos por empresas privadas que irão ter direto acesso ao conteúdo. Sempre verifique que não há informação privada de pessoas usuárias ou dados pessoais nos dados (exemplo: chaves privadas).
- Com mais prática você consegue construir uma boa intuição sobre que tipos de problemas a AI vai conseguir ou não te ajudar e o quanto de detalhes você precisa detalhar para cada tarefa. Mas vale lembrar que a tecnologia continua evoluindo e algo que não funcionava há 6 meses pode passar a funcionar com um novo modelo ou ferramenta.
O problema perfeito para IA envolver: entradas longas e/ou repetições de padrões e/ou uma implementação simples. Otimize essas situações, sempre!
Para humanos, ler vários arquivos ou analisar manualmente um texto longo é algo bastante demandante cognitivamente, mas LLMs conseguem fazer isso de forma extremamente rápida!
Um exemplo recente que aconteceu comigo: eu queria selecionar com o mouse apenas alguns números que eram mostrados em uma página web, mas quando eu tentava fazer isso, alguns outros caracteres também eram selecionados, devido ao layout da página.
Pensando no que fazer, eu poderia:
- Inspecionar a página web e tentar selecionar só os elementos relevantes…
- Pesquisar se existe alguma API para recuperar esses valores específicos…
- Codificar rapidinho um script em Python para limpar esse texto…
Mas aí, percebi que não precisava de nada disso! Eu só joguei o texto numa conversa com um Chatbot e pedi para me retornar apenas os números no texto. Funcionou certinho!
Importante: eu verifiquei manualmente alguns valores para garantir que o modelo não alucinou nenhum valor, e caso houvesse alucinação de um ou outro valor não seria um grande problema para o meu caso de uso.
Alguns outros exemplos corriqueiros do dia a dia que se enquadram bem nessa descrição de “problema ideal para a IA”:
Melhorar a qualidade de um código existente: geralmente, quando temos que implementar uma solução em uma linguagem que não somos especialistas, é difícil conhecer as melhores práticas dessa linguagem e é comum aplicarmos os padrões da linguagem que somos mais fluentes. LLMs sabem quais padrões utilizar e conseguem propor melhorias e boas práticas facilmente.
Segue um exemplo:
Nesse caso, a solução gerada pelo ChatGPT está correta, mas não é pythonica. Se pedirmos para a IA melhorar o código, ela consegue identificar o problema e corrigi-lo.

Apesar de, nesse caso, o modelo ter feito o que eu tinha em mente, note que eu não providenciei informações detalhadas de como o código deveria ser melhorado! “Coincidentemente” o modelo entendeu como melhoria algo que eu também tinha em mente, mas, quando utilizamos LLMs, a mesma regra do Zen do Python se aplica: Explicit is better than implicit ou seja explícito é melhor que implícito.
- Adicionar ou melhorar testes de unidades: “implemente um teste para a função X”. Quando já existem testes de unidades para o código, geralmente há um padrão bem estabelecido de como devem ser implementados e LLMs fazem um excelente trabalho em reproduzir esses padrões apenas com o contexto dos arquivos.Na minha experiência, meus testes gerados por LLMs tendem a ser mais completos e cobrir mais casos de uso. Porque convenhamos, escrever teste cobrindo todos os casos é chato, mas agora conseguimos ter uma excelente cobertura de código em segundos apenas pedindo para a IA ser exaustiva na geração dos testes.
- Geração de documentação: documentar um arquivo ou objeto, consiste basicamente em ler uma grande quantidade de código e comentários, entender a motivação para cada decisão e documentar de forma resumida tais decisões e considerações. Um caso perfeito para a IA, mas é interessante que uma pessoa especialista revise o código e adicione melhorias, já que, muitas vezes, o contexto para uma certa decisão de design ou de implementação pode não estar presente explicitamente no código.
- Scripts para análise e visualização de dados: scripts para análise de dados e para debugar algum erro são perfeitos para serem gerados com IA, já que muitas vezes é um código com uma estimativa de vida curta. Eu geralmente uso LLMs para deixar meus gráficos do matplotlib mais bonitos porque sempre esqueço a sintaxe da biblioteca .Segue um exemplo: peguei esse exemplo de gráfico na documentação do matplotlib (aqui):
Pedi para o Gemini 2.5 flash melhorar esse gráfico de uma forma bem genérica: “Make this plot prettier and more stylish” (Faça esse gráfico ficar mais bonito e com mais estilo). Segue o resultado:
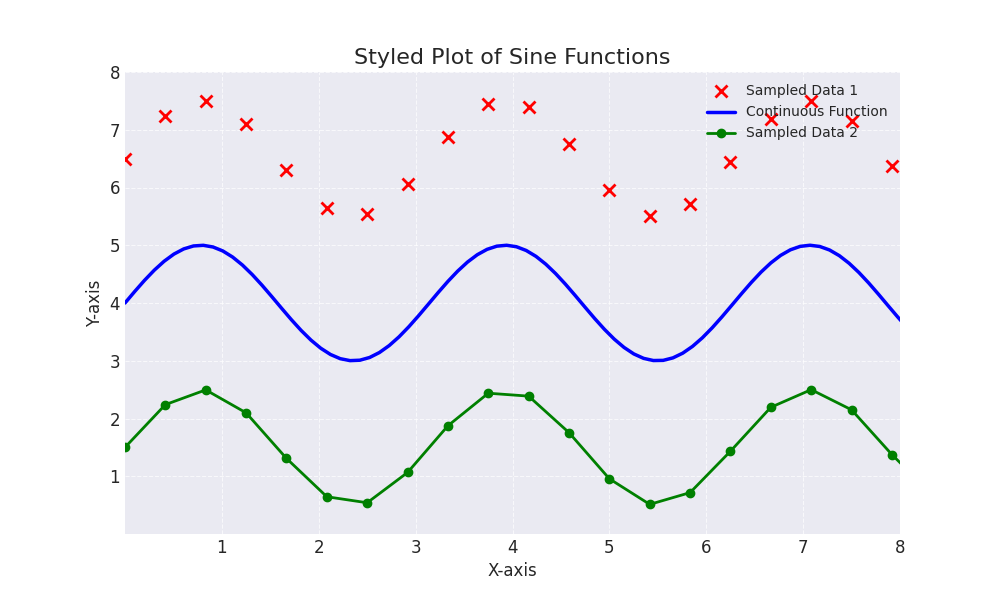
| Exercício: pesquise por uma linguagem de programação que você não tem familiaridade + uma biblioteca para visualização de dados nessa linguagem, escolha um exemplo de gráfico na documentação e tente melhorar o resultado final apenas pedindo para uma LLM.
Eu não resisti e tentei esse exercício também: aqui está o resultado da minha tentativa. |
Vibe coding
O que fizemos no exercício anterior é chamado de “vibe coding”. Esse termo foi “criado” num tweet do Karpathy (pois é, um tweet!) em que ele diz algo como:
“Tem um jeito novo de codar que eu chamo ‘vibe coding’: você se joga na vibe e até esquece que o código existe. Isso só é possível por causa das melhorias das LLMs (por exemplo: cursor composer com o modelo Sonnet)… Eu peço pelas coisas da maneira mais direta possível, porque eu tenho preguiça de olhar a documentação e procurar como fazer. Se eu vejo uma mensagem de erro eu só copio e colo o erro sem comentário no cursor, e geralmente o erro desaparece… Não é uma prática ruim para um projetinho para um final de semana, e é bem divertido. Eu consigo construir um projeto ou uma aplicação web mas sem codificar, eu só fico olhando, digitando umas coisas, rodando, copiando e colando outras coisas, e funciona na maioria das vezes”
Em termos mais técnicos “vibe coding” consiste em usar LLMs para prototipar ou construir basicamente um projeto inteiro do zero. Essa prática torna a criação de software extremamente mais acessível e mais rápida, especialmente para projetos ou protótipos simples.
A ideia seria seguir esses passos:
- Descrever para um LLM, a funcionalidade desejada, em linguagem natural (português, inglês etc)
- Receber do LLM um código que implementa essa funcionalidade
- Baseada na saída, que pode ser um site, um gráfico, um jogo etc. corrigir ou sugeri melhorias para a IA, em linguagem natural.
- Repetir os passos acima até obter um produto funcional.
Existem várias formas de desenvolver código com “vibe coding”. Por exemplo, o Canvas do Gemini, o replit e o claude.ai geram, além texto como saída, aplicações completas que permitem interações diretas com pessoas usuárias.
Abaixo estão alguns exemplos de aplicações que eu “criei” com essas ferramentas:
- Uma réplica do fruit ninja criada com o Canvas que a AI intitulou “word ninja” em que eu apenas expliquei como eu queria o funcionamento do jogo
2. Um exemplo de um jogo da cobrinha modificado
(você pode jogar nesse link: https://replit.com/@mariannelinhare/VibeCodingSnake)
| Exercício: agora é sua vez. Crie seu próprio aplicativo ou jogo com o replit (ou qualquer aplicação de IA de sua preferência) utilizando apenas vibes, ou seja, apenas linguagem natural! |
Agentes
Outra área em ativo desenvolvimento são os agentes. Em uma frase, agentes consistem em aplicações que dão aos LLMs o acesso a ferramentas (por exemplo: bash, um interpretador de python, um browser, calculadora, outros modelos de IA etc.) para executar tarefas complexas em nome das pessoas usuárias.
No contexto do desenvolvimento de software, a ideia é que, além de gerar o código, o LLM seja capaz de interagir com outras ferramentas de desenvolvimento. Por exemplo: além de implementar uma solução em Javascript, o agente pode formatar o código, adicionar testes, rodar os testes até que passem e comprovem a implementação correta, adicionar documentação, mandar os Pull Requests no GitHub, identificar e criar bugs etc. Basicamente realizar a maior parte das operações que uma pessoa desenvolvedora pode realizar.
Permitir a IA uma maior capacidade de “agência” abre novas oportunidades e muda ainda mais a nossa forma de pensar e construir software. Essa é a proposta do codex da OpenAI e do jules do Google.
O desenvolvimento do padrão MCP (Model Context Protocol) apresentado pela empresa Anthropic em novembro de 2024 foi um grande facilitador para o desenvolvimento de agentes. O MCP é um protocolo desenvolvido para padronizar como aplicações convencionais se “conectam” com LLMs.
A proposta é que em vez de termos APIs separadas para cada aplicação, que requer sua própria autenticação, decisões de design e segurança, entre outros itens, tenhamos uma única integração padronizada para todos os serviços.
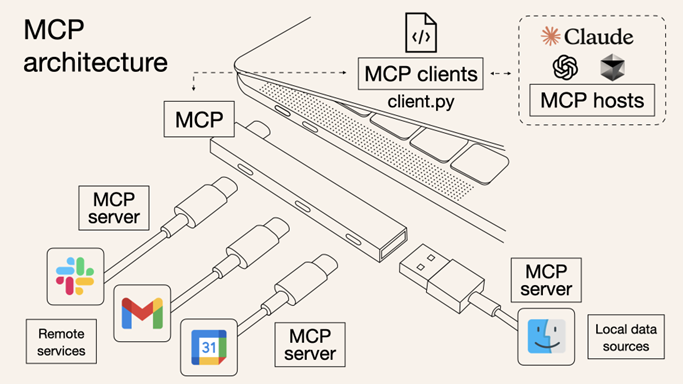
Imagem do blog “What is Model Context Protocol (MCP)? How it simplifies AI integrations compared to APIs”, por Norah Sakal
Essa é uma área em ativo desenvolvimento e, apesar de tornar LLMs muito mais poderosos, também torna os riscos de erros significantes maiores. Um exemplo recente foi explanado neste artigo da Invariant Labs (Maio 2025) em que os autores demonstram uma vulnerabilidade crítica no MCP Server oficial do GitHub, que permite aos atacantes acesso a dados de repositórios privados.
Conclusões
Desde o seu surgimento, o desenvolvimento de software nunca presenciou uma transformação tão radical. Em poucos anos, a inteligência artificial generativa não só alterou fundamentalmente a maneira como criamos aplicações, mas também barateou drasticamente a sua produção, tornando o software cada vez mais descartável.
Apesar de parecerem mágica, essas tecnologias não são perfeitas e não são a ferramenta ideal para todos os problemas. São, sim, ferramentas complementares que nos oferecem mais agilidade e possibilidades na construção de software e resolução de problemas. Nunca foi tão fácil ir de uma ideia para um protótipo funcional! Mas ainda não é trivial gerar um produto final capaz de resolver problemas no mundo real.
A tendência é que passemos mais tempo pensando e resolvendo as reais complexidades dos problemas, em vez de realizando tarefas repetitivas.
É bastante provável que, no futuro, a maior parte dos softwares seja gerada por LLMs em vez de humanos. Isso pode levar a uma menor diversidade de frameworks, bibliotecas e soluções, reforçando a hegemonia daquelas tecnologias que já estão bem representadas nos conjuntos de treinamento desses modelos.
Agradecimentos
Gostaria de agradecer o convite de participar desse evento! E, também, agradecer à Gabriela Surita pelo convite e por revisar o texto. Um abraço e até a próxima!
Referências
- Andrej Karphaty: Software 2.0
- Andrej Karpathy: Software Is Changing (Again)
- https://erikschluntz.com/software/2024/07/30/code-with-ai.html
- https://cloud.google.com/discover/what-is-vibe-coding
Este conteúdo faz parte da ProgaMaria Sprint IA Generativa
Autora
Marianne Linhares Monteiro é Engenheira de Machine Learning na Google DeepMind há quase 6 anos. É natural João Pessoa (PB), formada em Ciência da Computação na Universidade Federal de Campina Grande. Tem interesse por IA, tecnologia, educação, música e qualquer coisa que misture esses tópicos. https://www.linkedin.com/in/mariannelinharesm/
Revisora
Luciana Fleury, jornalista https://www.linkedin.com/in/luciana-fleury-1b024083/
Muito bom!
Sou da área de UX/UI Design e super curiosa sobre IA, ultimamente tenho experimentado codificação, por enquanto só HTML e CSS. Já quero experimentar as demais IA para tirar ideias do papel e aprofundar o conhecimento em programação.
Obrigada pelo o artigo!