
Manter-se disponível para ir além dos limites convencionais do aprendizado de máquina contribuiu para entregar soluções mais impactantes para a resolução de problemas
Esta é uma carta aberta de uma cientista de dados para qualquer pessoa que busca orientação para ingressar no campo. Eu não sou do tipo que oferece um artigo com opiniões leves, mas sinto que está ocorrendo um descompasso entre a idealização de quem quer se tornar cientista de dados e a realidade das expectativas e requisitos do trabalho. Então, aqui estou eu, oferecendo a opinião de uma pessoa, baseada “a posteriori“, ou seja, em minhas experiências e trajetória profissional.
O descompasso que está ocorrendo é, talvez, uma batalha de terminologias, mas a terminologia que usamos é indicativa das expectativas do campo. Então, deixe-me primeiro explicar algumas terminologias. Inteligência artificial representa amplamente o conceito de um programa de computador demonstrando, ou imitando, inteligência semelhante à humana. A aprendizagem de máquina é um subconjunto da inteligência artificial, no qual as máquinas utilizam dados e algoritmos para aprender essas inteligências humanas e criar modelos que as representem. A visualização predominante associada a essa definição é um diagrama de Venn, mais ou menos assim:
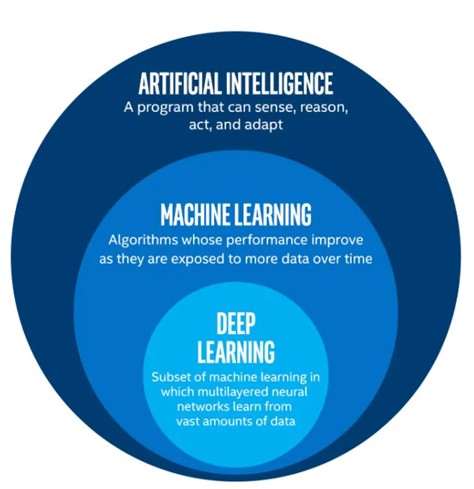
Figura 1: Venn diagram of AI vs ML vs DL
Agora, quanto ao descompasso. Quem ingressa no campo geralmente se foca no subconjunto de aprendizado de máquina. Pesquise na internet por “o que é ciência de dados” e você encontrará algo como o uso de dados para responder a perguntas e fornecer informações comerciais significativas. O próximo salto lógico é o “como”? É aqui que o trabalho tem sido glorificado com o aprendizado de máquina, o aprendizado profundo e, mais recentemente, os modelos de linguagem grandes. A percepção comum é que o “como” consiste em realizar uma análise exploratória de dados, limpeza de dados e, em seguida, criar um modelo de aprendizado de máquina que forneça as informações desejadas.
A realidade é que essa percepção simplesmente não é verdadeira em muitos casos. O aprendizado de máquina não deve ser a primeira solução para qualquer problema. Existem vários pré-requisitos que precisam ser atendidos antes que o aprendizado de máquina seja considerado e, muitas vezes, esses pré-requisitos não podem ser atendidos. Mas isso não significa que tudo está perdido; o problema apenas precisa ser reformulado de uma maneira que possa ser resolvido.
Para reformular corretamente o problema, é necessário pensar de forma holística. Responda a isso antes de continuar lendo: na Figura 1 acima, quais são exemplos de técnicas que estariam dentro da bolha de inteligência artificial, mas não dentro da bolha de aprendizado de máquina? É aqui que eu afirmo que cientistas de dados devem ampliar seu arsenal de técnicas para ser eficaz no campo. Eu encorajo aspirantes e juniores cientistas de dados a substituírem suas concepções de ciência de dados da Figura 1 pela Figura 2 abaixo.
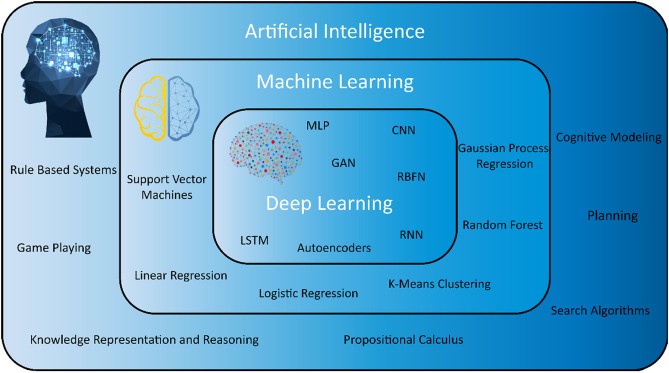
Figura 2: Broadened Scope of AI vs ML vs DL
Agora, apresento as evidências para respaldar minha opinião. Gostaria de enumerar uma variedade de casos de uso que encontrei em meus sete anos como cientista de dados e como eles foram abordados e por quê.
CASO DE USO 1: Previsão de qualidade de síntese de DNA
Resumo: O DNA pode ser sintetizado por máquinas muito precisas que injetam reagentes de elementos base e passos de encadeamento para criar sequências personalizadas. Essas máquinas operam em milissegundos e possuem uma abundância de sensores para monitorar o processo. Embora sejam altamente precisas, as reações químicas desejadas não são garantidas, e truncamentos e mutações podem ocorrer. Esse risco aumenta à medida que o comprimento da sequência aumenta. O objetivo do projeto era identificar, durante a síntese, se a qualidade de uma sequência havia degradado além de limites aceitáveis. Os custos de reagentes e tempo de máquina estavam na faixa de US$ 10.000 por hora, portanto, qualquer previsão que indicasse a interrupção de uma execução tinha um alto potencial de economia.
Após a análise de dados históricos e a identificação de padrões na série temporal, foi desenvolvido um fluxo de trabalho de heurísticas personalizadas que podiam avaliar a qualidade das cadeias de DNA sintetizadas. Isso possibilitou a identificação mais eficiente e precisa de possíveis problemas, permitindo intervenções proativas e melhoria geral dos processos de síntese de DNA.
Técnica utilizada: análise de séries temporais
Justificativa: A qualidade dos dados, em sua maioria, era boa, pois os dados vinham de sensores IoT das máquinas. Leituras ocasionais anormais foram facilmente detectadas e suavizadas conforme apropriado. O conjunto de dados não continha rótulos, portanto, o problema se enquadrou no espaço não supervisionado. Por meio do trabalho com especialistas no assunto, identificou-se que as anormalidades eram de alta importância. Dadas as condições prévias de aprendizado não supervisionado e detecção de anomalias em séries temporais, foi selecionada uma abordagem de pesquisa de similaridade com “dynamic time warping“.
CASO DE USO 2: Relatórios de produtividade na agricultura
Resumo: A agricultura de precisão é a arte de observar e otimizar processos agrícolas, principalmente com o objetivo de aumentar a produtividade das colheitas. Ao iterar em configurações de otimização, torna-se crítico observar, medir e visualizar com precisão a produtividade das colheitas para comparar o desempenho entre cada configuração. A produtividade das colheitas depende muito de uma infinidade de fatores, muitos dos quais são incontroláveis.
Após incorporar conhecimento especializado e regras específicas do domínio em um sistema baseado em conhecimento, foi criada uma solução que podia analisar dados agrícolas e gerar relatórios abrangentes sobre a produtividade das colheitas. Isso capacitou agricultores e profissionais agrícolas a tomar decisões informadas sobre o manejo das colheitas, alocação de recursos e produtividade geral.
Técnica utilizada: representação e raciocínio baseados em conhecimento
Justificativa: Para iterar rapidamente, era necessário ter uma suíte abrangente de relatórios descritivos que pudessem ser facilmente consumidos por especialistas do domínio. Diversas análises de dados e representações estatísticas do desempenho da iteração foram relatadas. Dada a natureza geográfica dos dados (campos de cultivo sobrepostos), técnicas de suavização de dados com Generalized Additive Models (GAMs) foram altamente eficazes. Nenhum aprendizado de máquina foi incorporado nesse projeto, pois as necessidades não exigiam nada mais sofisticado do que análise descritiva.
CASO DE USO 3: Suporte à manutenção de aviação
Resumo: A manutenção de aeronaves para companhias aéreas é um esforço detalhado e, muitas vezes, tedioso. Cada aeronave possui de 3 a 6 milhões de peças, dependendo do modelo. A manutenção pode ser programada ou não programada, sendo que a manutenção não programada é baseada em relatórios de discrepâncias escritos por técnicos de manutenção de aviação, pilotos, equipe de voo, equipe em solo ou outros. Ao avaliar esses relatórios de discrepâncias para resolução, pode ser necessário um trabalho significativo de solução de problemas para determinar a causa raiz. Esse esforço de solução de problemas se torna exponencial para técnicos mais novos, já que os manuais de manutenção são vastos e exigem muito tempo para serem aprendidos.
A declaração do problema era identificar as cinco causas mais prováveis para um determinado relatório de discrepância.
Técnica utilizada: processamento de linguagem natural; agrupamento (clustering)
Justificativa: Os dados eram texto livre e não continham rótulos. As técnicas de inteligência artificial, como sistemas especialistas e raciocínio baseado em regras, foram testadas sem sucesso. Foi então determinado que os rótulos eram uma exigência para o sucesso. Para rotular os dados, foi utilizado o processamento de linguagem natural para analisar os relatórios e, em seguida, foi aplicado o agrupamento para auxiliar nos esforços de rotulagem manual.
Uma vez que os rótulos foram estabelecidos (e revisados por especialistas no assunto), foi treinado um modelo de aprendizado de máquina supervisionado para classificar os relatórios em uma lista predefinida de possíveis categorias de problemas. Esse caso de uso foi um exemplo interessante em que tentativas não baseadas em aprendizado de máquina foram malsucedidas e o problema foi redefinido com novos requisitos de rótulos.
CASO DE USO 4: Segurança do motorista no interior da cabine para transportadoras
Resumo: Muitas medidas de segurança foram implementadas na indústria de transporte para melhorar a segurança dos motoristas, incluindo restrições sobre quantas horas um motorista de caminhão pode dirigir. No entanto, os motoristas de caminhão ainda estão sujeitos a riscos de segurança, como sonolência, distração, comportamento de direção inadequado ou outros problemas de trânsito. Câmeras no interior da cabine do caminhão estão disponíveis e transmitem imagens de vídeo que podem ser analisadas para ajudar os motoristas. Além disso, dados de telemetria (como a pressão dos freios) do caminhão também estão disponíveis. O objetivo é criar um sistema que forneça feedback em tempo hábil aos motoristas, permitindo que eles tomem medidas corretivas e evitem acidentes, promovendo, assim, um ambiente de transporte mais seguro.
Técnica utilizada: visão computacional
Justificativa: Dado que o conjunto de dados incluía imagens de vídeo, este era um caso de uso claro para técnicas de aprendizado profundo em visão computacional. A visão computacional é a técnica predominante para interpretar dados de vídeo e imagem.
CASO DE USO 5: Suporte à tomada de decisão em pedidos oferecidos no transporte
Resumo: Os remetentes têm carga que precisa ser transportada e as transportadoras são aquelas com caminhões para movê-la. Os remetentes comunicam suas necessidades de transporte por meio da oferta de cargas às transportadoras, que contêm detalhes como onde a carga precisa ser retirada e entregue. As transportadoras geralmente recebem de centenas a milhares de ofertas de cargas por dia e podem ficar sobrecarregadas com quais aceitar. Muitos fatores estão em jogo, como lucro potencial, motoristas e caminhões disponíveis e atributos da carga que a tornam viável ou inviável para a execução – como o equipamento necessário.
O objetivo desse caso de uso é criar uma solução que auxilie as transportadoras a tomarem as decisões mais adequadas em relação às cargas oferecidas, a fim de otimizar seus negócios.
Técnica utilizada: sistemas baseados em regras; lógica fuzzy
Justificativa: Os dados necessários (dados de ofertas de cargas e dados operacionais históricos das transportadoras) são principalmente de formato livre e campos personalizados são comuns. A entrada de dados possui pouca ou nenhuma validação para sanidade ou qualidade, tornando os dados de baixa qualidade. Além disso, os fatores envolvidos na tomada de decisão são nuances, estão sempre em movimento e muitas vezes entram em conflito uns com os outros. Por exemplo, uma transportadora pode ter que decidir qual é mais importante naquele momento, levar um motorista para casa ou obter lucro. Dadas essas restrições em uma possível solução, os sistemas baseados em regras oferecem flexibilidade e explicabilidade que se adequam bem ao problema. A lógica fuzzy também foi utilizada para incorporar raciocínio semelhante ao humano com dados imprecisos e incompletos. Em geral, os dados eram de qualidade muito baixa e o espaço do problema era muito sutil e dinâmico para o aprendizado de máquina ser prático.
Conclusão
Ao longo de minha trajetória profissional, percebi o valor de abordagens diversas em ciência de dados além do aprendizado de máquina. Cada projeto apresentava desafios e requisitos únicos, e, ao explorar técnicas de IA alternativas, foram fornecidas soluções personalizadas que melhor se adequavam aos espaços de problemas específicos. Ao incorporar análise de séries temporais, representação do conhecimento, processamento de linguagem natural, visão computacional, sistemas baseados em regras e lógica fuzzy, expandi meu repertório como cientista de dados e contribuí para resolver problemas complexos em várias indústrias.
Essas experiências reforçaram minha crença de que cientistas de dados versáteis devem manejar com habilidade suas caixas de ferramentas e explorarem além dos limites convencionais do aprendizado de máquina. Ao abraçar abordagens diversas em ciência de dados, podemos descobrir novos insights, entregar soluções mais impactantes e, em última análise, fazer uma diferença significativa nas indústrias que atendemos. Quebrar as barreiras do molde de aprendizado de máquina nos permite aproveitar todo o potencial da ciência de dados e da inteligência artificial.
Autora Tawni Marrs, Lead Data Scientist na Trimble
Especialista em dados oriunda da ciência da computação, tem experiência em engenharia de big data e uma mentalidade voltada para resolver problemas com dados. Trabalhou em vários setores, incluindo agricultura, aviação e síntese de DNA. Atualmente lidera uma equipe de cientistas e engenheiros de dados em transporte. Sua motivação é preencher as lacunas entre produto e tecnologia em diferentes setores. Revisora Luciana Fleury, jornalista
Este conteúdo faz parte da PrograMaria Sprint Tech Leads.
Boa tarde! Nada melhor do que a experiência para ampliar nossa visão, a partir de situações reais, diferentes possibilidades na busca de soluções
Gratidão