


O passo a passo completo para desenvolver seu primeiro projeto de Machine Learning
No workshop Primeiros passos com Machine Learning: transformando dados em conhecimento! com Fernanda Wanderley (Cientista de Dados na Neuralmed), vamos simular a rotina de uma cientista de dados que utiliza algoritmos de Machine Learning para resolver desafios. Vamos trabalhar com dados reais a partir de um repositório público, passando por todas as etapas: tratamento dos dados, análise exploratória, criação e treinamento do modelo, e avaliação dos resultados! Nosso desafio?
Treinar um modelo de Machine Learning baseado em um algoritmo de aprendizado supervisionado chamado regressão. Depois de treinado, nosso modelo vai ser capaz de inferir a nota de determinado filme no ranking do IMDB! 📽️ Com o conhecimento deste workshop, vocês conseguirão explorar e analisar outros conjuntos de dados!

Para esse workshop é necessário conhecimento de alguma linguagem de programação, especialmente Python, e familiaridade com linha de comando.
Caso você já conheça uma linguagem de programação (JavaScript, Java, PHP, C, C++ etc), mas não conhece Python, sugerimos dar uma olhada nesse guia Python Para Programadoras para se familiarizar com a linguagem.
Caso você não tenha nenhum conhecimento em programação, recomendamos que você se desafie e assista ao workshop mesmo assim, se concentrando em entender os conceitos e o que acontece nas etapas. A linguagem é só o como traduzir os conceitos para a máquina e você poderá aprender isso depois, se quiser. Depois de ver o workshop, se se sentir confortável, você pode tentar seguir o passo a passo, pausando o vídeo quando precisar. Se tiver dificuldade, antes de pedir ajuda, encorajamos você a tentar entender o que está acontecendo, jogue no Google eventuais mensagens de erros que aparecerem e construir de forma ativa sua aprendizagem. E fique tranquila se não conseguir, esse workshop é para quem já tem experiência! 😉 Se você gostou de Python, recomendamos esse curso introdutório gratuito para fazer: Python para zumbis do Fernando Masanori.
Neste artigo, vamos deixar todo ambiente, ferramentas e bibliotecas prontos para você ter tudo que precisa para acompanhar o workshop! Vamos nessa? =)
Preparando seu ambiente de Cientista de Dados
-
- Instalar Python
- Preparar um ambiente virtual
- Instalar Bibliotecas
- Instalar Jupyter Notebook
- Separar recursos necessários
Escolha sua linguagem de programação: Instalando Python 3
Para escrever/programar nosso modelo, usaremos a linguagem de programação Python, na versão 3, (R!, Scala, SAS também são comumente usadas na área de Ciência de Dados e possuem suas respectivas bibliotecas), caso você ainda não tenha instalado no seu computador, faça essa instalação. Aqui tem um guia com o passo a passo de como fazer: https://tutorial.djangogirls.org/pt/python_installation/
Criando um ambiente virtual: Configuração do virtualenv
Se instalarmos as ferramentas e bibliotecas diretamente na sua máquina, pode haver interferência nas ferramentas previamente instaladas no seu sistema operacional, como versão do Python, bibliotecas etc. Para evitar esse problema, uma boa prática quando estamos começando um novo projeto é configurar um ambiente virtual. Ele cria uma instância separada na qual você também controla a configuração de versões de ferramentas necessárias para esse workshop sem interferir no restante! Com o ambiente virtual, você garante um ambiente isolado para explorações! 🙂
Siga o passo a passo para configurar o seu de acordo com seu sistema operacional:
Windows
- No terminal (caso nunca tenha mexido com terminal, recomendamos ler este artigo para entender o que ele faz :) do Windows (iniciar > digite: cmd) digite o comando
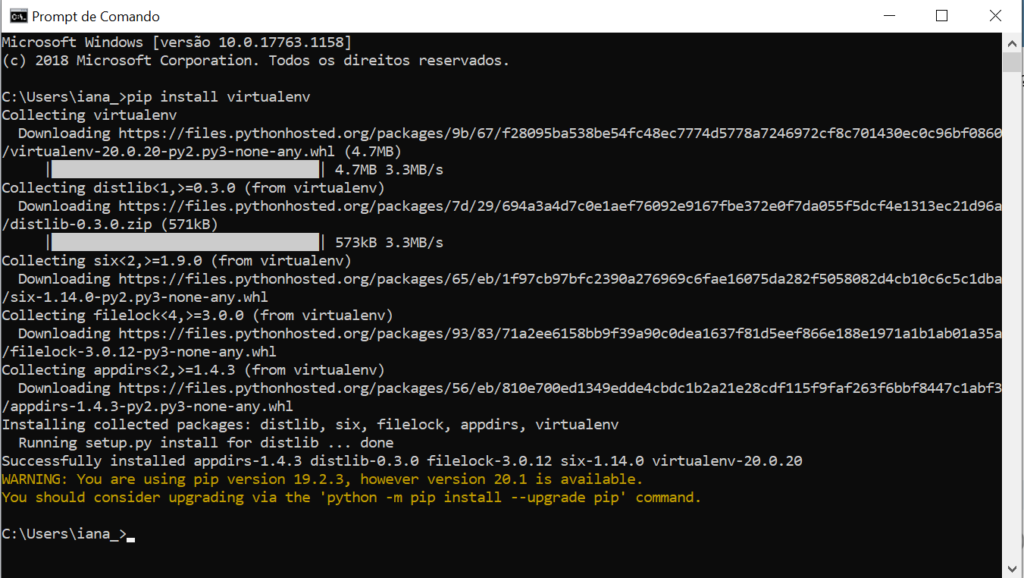
2. Criar o ambiente virtual na pasta chamada programaria com o comando
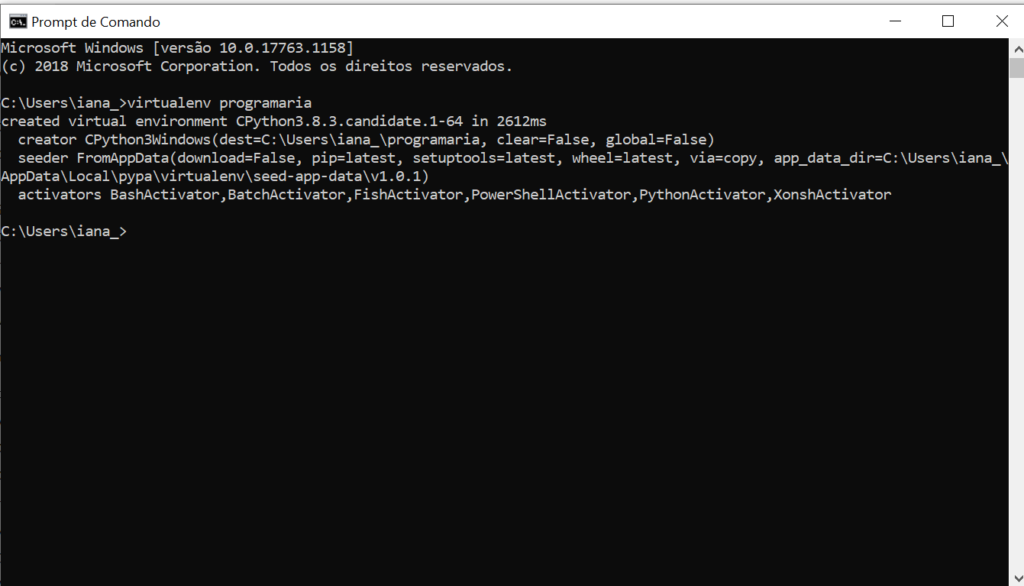
Se você fez todo o tutorial até aqui, e o comando virtualenv não foi reconhecido como comando, tente este comando alternativo:
3. Ativar o recém-criado ambiente virtual chamado programaria com o comando
Observe que você deve usar o caminho completo de onde está a sua pasta programaria (no nosso caso, no Disco Local C>pasta Users>subpasta iana_) para que o computador consiga localizar corretamente o arquivo necessário. (Caso precise, você pode procurar pela interface do explorador de arquivos e pastas (teclas windows + e) para verificaronde criou a pasta programaria)
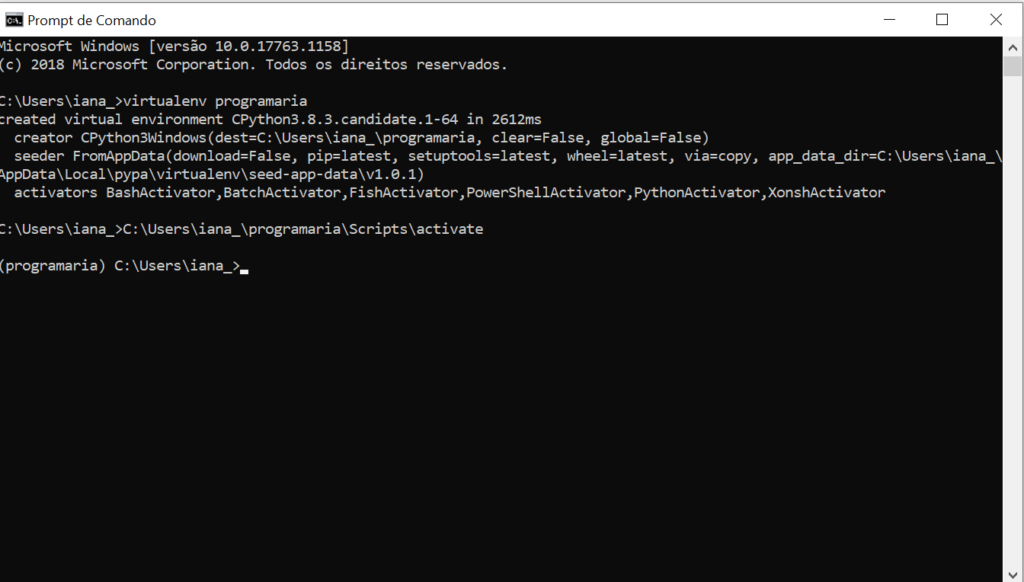
O ambiente estará funcionando quando, antes do nome do seu usuário e máquina, aparecer o nome atribuído a ele entre parênteses. No nosso caso, (programaria), como aparece na imagem acima.
Linux/Mac
Com o Python3.x já instalado é hora de instalar o virtualenv
fernanda@caipora2:~$python3 -m venv sudo apt-get install python3-venv
Depois de instalado, criaremos um ambiente virtual durante o nosso workshop, chamando de “programaria”, e o ativaremos. Siga as duas linhas códigos da imagem para criar o ambiente:

O ambiente estará funcionando quando, antes do nome do seu usuário e máquina,aparecer o nome atribuído a ele entre parênteses. No nosso caso, (programaria), como aparece na terceira linha da imagem.
Para desativar o ambiente é só usar o comando
Depois do workshop você pode desinstalar deletando a pasta que criou para o virtualenv, no caso a pasta “programaria”.
Escolha suas ferramentas: Instalando bibliotecas
Já temos a linguagem, agora precisamos de algumas ferramentas que nos ajudem nessa tarefa. Aí é que entram as bibliotecas! Já existem diversas bibliotecas que facilitam o trabalho da Cientista de Dados. Elas fornecem ferramentas pré-prontas para mineração, análise de dados, estrutura de dados, funções, algoritmos de machine learning, pacotes gráficos e outros tipos de recursos necessários no dia a dia da área de Ciência de Dados. Com poucas linhas de código, você consegue realizar uma análise exploratória e criar modelos simples!
Neste workshop, vamos usar três bibliotecas Python para Análise de dados, Machine Learning e Visualização de Dados: Pandas, Scikit-learn e Matplotlib, respectivamente. Existem várias outras!
1. Biblioteca Estatística: Pandas
É uma das mais famosas bibliotecas para Ciência de Dados em Python, por trazer ferramentas de análises de dados e estruturas de dados de alta performance e fáceis de usar. “O Pandas contêm muitos métodos internos para agrupar, filtrar e combinar dados, bem como a funcionalidade de séries temporais.” (Top 20 bibliotecas Python para Data Science). Para instalar a biblioteca Pandas, usaremos um comando simples no terminal (linha de comando) do seu computador que funcionará tanto para Windows como Linux e MAC. Certifique-se de que você está trabalhando no ambiente virtual que acabou de criar. (Só ver se tem o (programaria) antes.
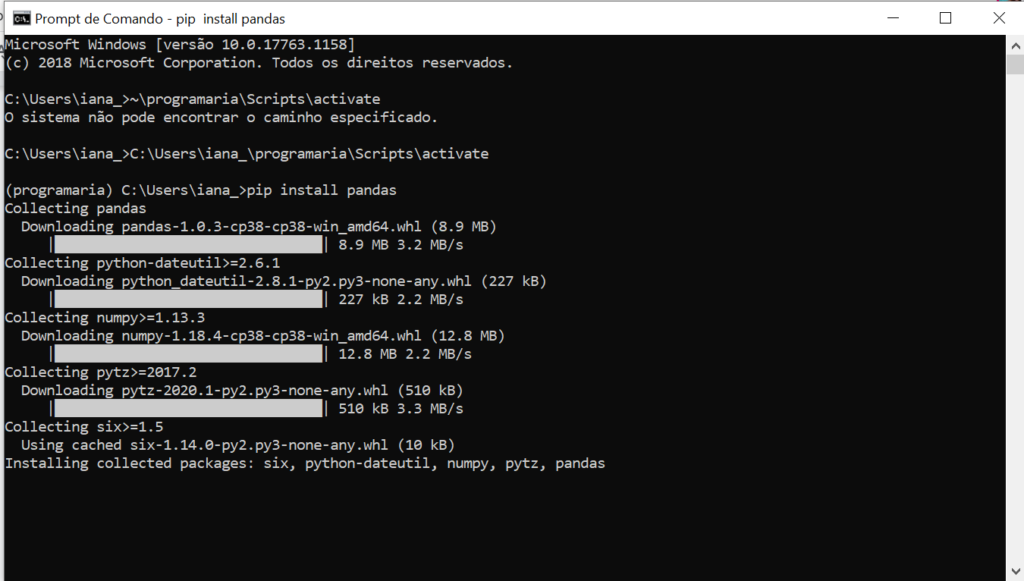
Observe que ele instala Numpy e outros pacotes necessários! O artigo Seus primeiros passos como Data Scientist: Introdução ao Pandas! dá uma introdução às principais ferramentas de manipulação, leitura e visualização do pandas e recomendamos que você leia o post e tente, se possível, executar os trechos de código disponíveis!
2. Biblioteca de Machine Learning: Scikit-learn
Como vimos, os algoritmos de Aprendizado de Máquina (Machine Learning) são desenvolvidos em sua maioria por pesquisas acadêmicas e disponibilizados para que outras pesquisadoras, profissionais e empresas utilizem em aplicações.Este módulo é considerado uma das melhores bibliotecas para trabalhar com dados. “Ele fornece algoritmos para muitas tarefas padrão de aprendizado de máquina e mineração de dados, como clustering, regressão, classificação, redução de dimensionalidade e seleção de modelo” (Top 20 bibliotecas Python para Data Science)
Para instalar o Scikit-learn, usaremos um comando simples no terminal (linha de comando) do seu computador
3. Bibliotecas de Visualização de dados: Matplotlib, Seaborn e Plotnine
Para criar as visualizações dos nossos dados, ver diagramas e gráficos, usaremos três bibliotecas de construção de diferentes gráficos que vão ajudar a interpretar melhor os dados e os resultados obtidos com nosso modelo. Para instalá-los, usaremos um comando simples no terminal (linha de comando) do seu computador, um de cada vez:
Escolha sua interface: Instalando Jupyter Notebook
Tendo a linguagem e as bibliotecas é hora de preparar a interface onde vamos realizar nossos experimentos.
A interface/IDE que vamos usar para desenvolver nosso projeto de Ciência de Dados será o Jupyter Notebook, ele é uma aplicação de código aberto que permite unir código e texto, além de equações, visualizações de dados e até elementos HTML. Ele é usado por cientistas de dados no momento dos experimentos – geralmente quando o código e o modelo estão maduros, esse código é salvo num arquivo .py para rodar diretamente na linha de comando.
O Jupyter também é útil para apresentar seus projetos e resultados para as pessoas interessadas, os chamados stakeholders (essa é uma etapa extremamente importante, pois é aqui que você convence as pessoas de o modelo criado no seu projeto vai gerar valor para o negócio)! Por permitir alterar o código, rodar ali na própria máquina e ver o resultado em tempo real, ele também é uma ótima ferramenta para workshops. Ah! E ele funciona para outras linguagens também, como R!
Para instalar o Jupyter, usaremos um comando simples no terminal (linha de comando)
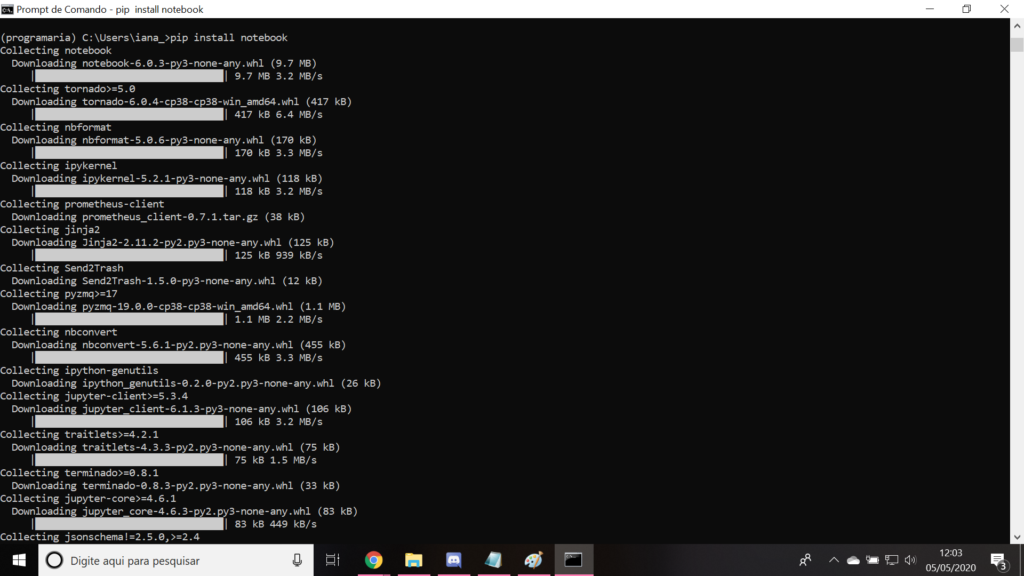
Ele vai instalar várias coisas, serão várias linhas. Fique tranquila! 🙂
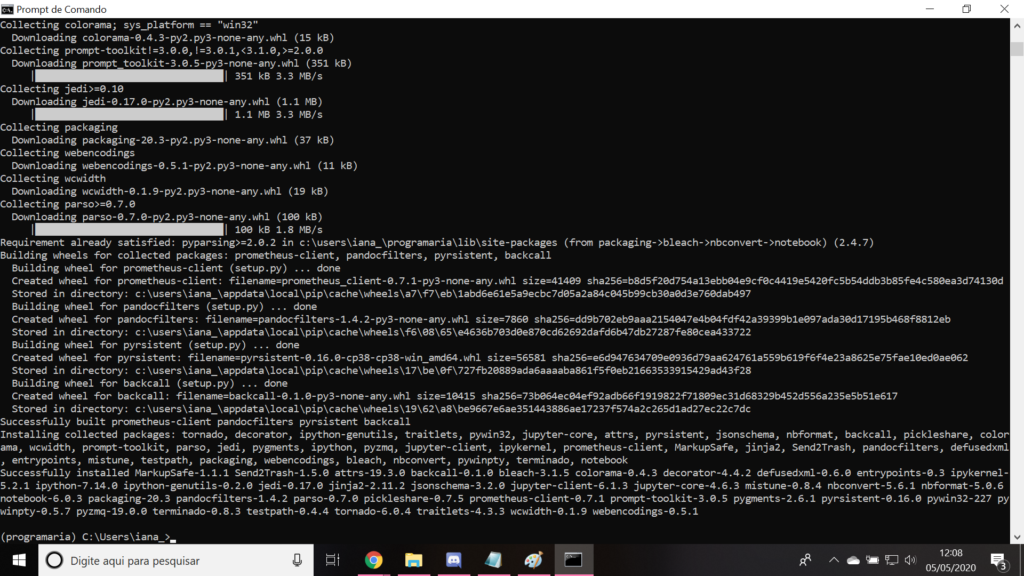
Quando terminar, aparecerá essa imagem acima.
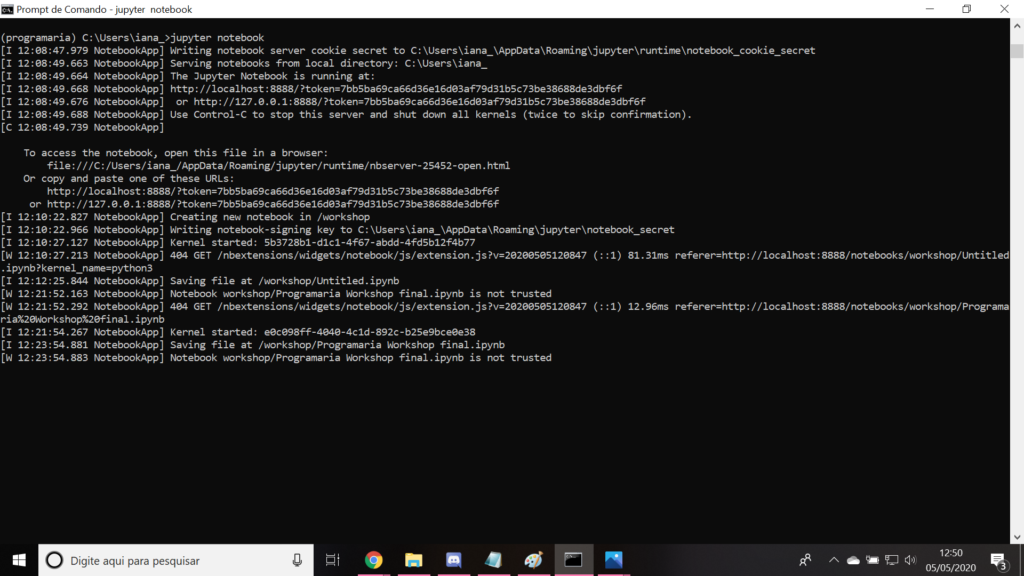
Para inicializar o jupyter basta digitar jupyter notebook na linha de comando e ele será carregado numa aba do seu navegador.
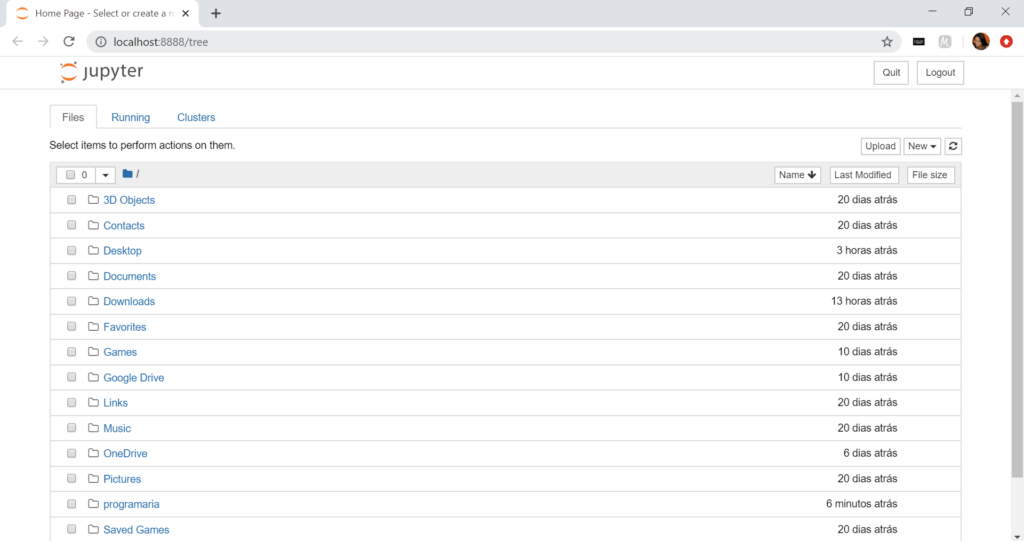
Para criar um novo arquivo no jupyter, basta clicar em new.
Prontinho! Agora seu ambiente de cientista de dados está configurado! Falta só separar os materiais necessários para o workshop! 🙂
Separar recursos necessários: dataset, arquivo referência e proatividade
Já falamos que a matéria prima da cientista de dados são… os dados! 😛 Neste workshop, vamos trabalhar com os dados do Kaggle, uma plataforma que funciona como uma comunidade online de cientista de dados, em que você pode encontrar e publicar datasets, além de explorar e construir modelos com outras pessoas, além de participar de competições para resolver desafios em de Ciência de Dados e Machine Learning. Basicamente, seu novo melhor amigo se você quiser seguir pela área! 🙂
1. Dataset
Os dados nada mais são do que tabelas imensas, com várias linhas e colunas. Eles podem vir de diversas fontes, públicas ou internas da própria empresa, como as séries históricas de venda e preços praticados que a Juliana Cesaro usou no modelo para prever melhor a demanda e o preço no Magazine Luiza, por exemplo. No workshop, utilizaremos o arquivo de conjunto de dados (dataset) de filmes do IMDB disponível para download neste link (é preciso se registrar na plataforma) e aqui vai uma outra boa prática: para salvar os arquivos de trabalho do workshop, crie uma nova pasta chamada workshop no mesmo local em que você criou a pasta programaria, onde está rodando o seu ambiente virtual. (pode fazer pela interface do explorador de pastas e arquivos). Essa pasta será sua pasta de trabalho, em que você salvará os arquivos e códigos que desenvolver durante o workshop. Não é recomendável salvar na pasta programaria, porque, se você deletar o ambiente virtual, você deletará todo o trabalho feito junto! Assim, preservamos o resultado do seu esforço! 🤗
Criar pasta workshop no mesmo local em que está a pasta programaria
O arquivo estará zipado, então será preciso descompactar. Aproveite para transferir o arquivo movie_metadata.csv para a pasta workshop, assim ficará tudo à mão durante o workshop! 🙂
Arquivo movie_metadata.csv na pasta woskhop
2. Baixando Jupyter Notebook de referência
Como vimos, o Jupyter é uma aplicação de código aberto que permite unir código e texto, e disponibilizamos o arquivo comentado com todos os códigos utilizados no workshop! Baixe para sua pasta workshop. Para abrir este arquivo, basta encontrar a pasta workshop na lista do Jupyter que você acabou de abrir no seu navegador e clicar no arquivo Programaria Workshop final.ipynb, ele vai abrir em outra aba e você já poderá usar quando for assistir ao workshop para conferir os códigos que a Fernanda Wanderley vai usar!
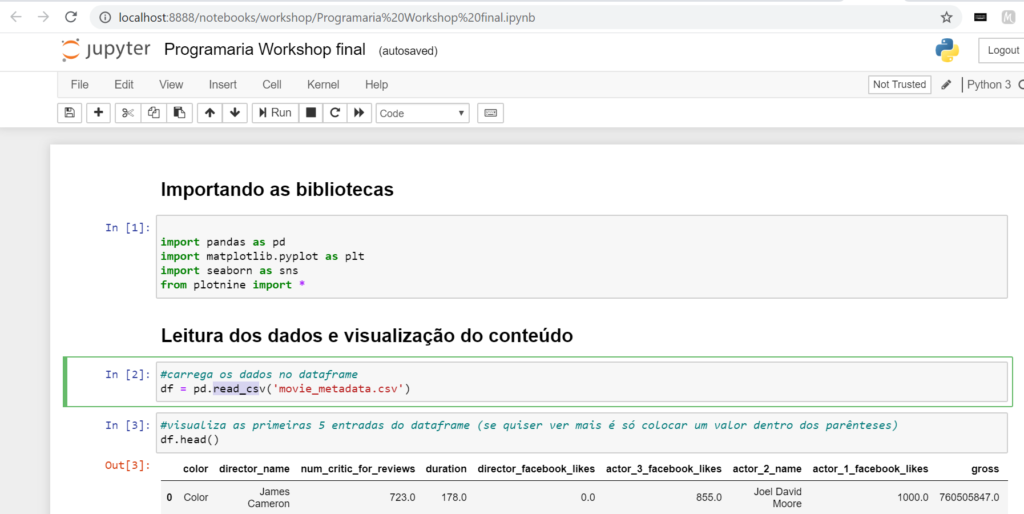
Programaria Workshop final.ipynb
3. Proatividade, colaboração e energia!
Uma das principais características de uma pessoa que trabalha com tecnologia é aprender a aprender e isso está MUITO baseado em proatividade! Ficou com uma dúvida ou deu errado? Reflita sobre o que está acontecendo, tente entender qual erro está dando, busque no Google possíveis soluções (às vezes só de jogar a mensagem de erro você já encontra a solução). A outra ferramenta é a colaboração: converse com pessoas que estão no mesmo desafio, ajude quem puder, faça perguntas e evolua seu raciocínio! Isso é fundamental para seu aprendizado! Por fim, energia é sempre bom, né? Então, se espreguiça, descansa os olhos, respira fundo e vamos nessa! 😀
Tudo pronto para assistir ao Workshop!
Tira uma selfie pra registrar esse momento, posta nos stories com #SprintPrograMaria, marca @programaria e bora! 😉
Terminou o Workshop?
Atividade para Fórum (Para quem está inscrita na Sprint PrograMaria – IA para Devs, compartilhar no canal #modulo-3-atividade)
Agora que você já entendeu o ciclo de trabalho de uma pessoa cientista de dados. Que tal compartilhar seus testes e explorações?
- Análise exploratória: comente sobre o que você conseguiu aprender com os dados
- Análise que você fez e aplicou: a que conclusão você chegou? Qual correlação entre as features que você escolheu e a pontuação do filme?
- Desafio: escolher outra das categorias para prever (gênero do filme, por exemplo)
-
-
Próximos projetos
Agora você já sabe o básico sobre como criar método ML e pode explorar outros datasets! O Kaggle é uma excelente fonte de datasets e desafios para brincar! Sugerimos dois tutoriais com alguns desafios que você pode fazer com o mesmo ambiente e pacotes que já instalou no workshop:
- Prever quais passageiros tem chances de sobreviver ao desastre Titanic.
- Criar um algoritmo que consegue identificar a espécie correta de uma flor a partir de suas medidas
Divirta-se! 🍝
Referências para ir além
- Estatística Necessária para Data Science
- Entendendo o que é Matriz de Confusão com Python
- Melhores práticas de Machine Learning + Glossário (Google, em inglês)
- Conceitos básicos sobre Data Science (em inglês)
- Palestra Afinal, o que é esse tal de Machine Learning? – Carla Vieira – Guru-SP
Nesta palestra, Carla Vieira mostra como executou uma tarefa de clusterização (aprendizado não-supervisionado) para agrupar de forma automática diferentes notícias por grupos semelhantes ou relacionados, utilizando o algoritmo k-means!
Ola, excelente vídeo, aprendi muito e ja sei como iniciar o meu trabalho para a faculdade, mas tenho uma duvida é besta.
Voce diz para fazermos o teste, pegado e adicionando um filme nos arquivo, nao compreendi como faço esse teste, poderia me dizer. Como pego um filme e passo ele no modelo
Oi, Pedro!
Este artigo foi publicado pela PrograMaria e escrito pela Fernanda Wanderley, então você pode perguntar diretamente a ela: LinkedIn.
Eu tenho uma duvida com realção aos valores preditos. Por exemplo o modelo me retorna uma array com os valores, como tranformar ele numa coluna pra exportarmos os resultados em csv por exmeplo? Sabendo que tiramos a coluna com a nota do filme pára que o modelo nos desse esses valores